05 Sep 2017
|
라즈베리파이
리눅스
화면 캡쳐 프로그램 scrot
scrot 설치
다음 명령어를 이용하여 scrot 프로그램을 설치합니다.
$ sudo apt-get install scrot
화면 캡쳐 방법
가장 간단하게 하는 방법으로는 단순히 scrot 명령어를 실행하는 것입니다. 화면이 캡쳐되면 현재 디렉토리 안에 png 형식으로 파일이 저장됩니다.
-d 옵션을 이용하면 화면 캡쳐에 딜레이를 설정 할 수 있습니다.
화면의 일부만 캡쳐하고 싶을 때는 -s 옵션을 줘서 마우스도 드래그하여 영역을 설정할 수도 있습니다.
04 Sep 2017
|
라즈베리파이
리눅스
samba를 이용하여 라즈베리파이를 NAS처럼 사용하기
samba를 이용하면 라즈베리파이의 파일들을 보다 쉽게 공유할 수 있습니다. 특히 라즈베리파이에 USB 메모리 등을 연결했을 때, 그 USB 메모리를 마치 NAS처럼 사용할 수도 있습니다.
samba 설치
다음 명령어를 이용해서 samba를 설치합니다.
$ sudo apt-get install samba
$ sudo apt-get install samba-common-bin
USB 메모리를 연결
라즈베리파이에 USB 메모리를 연결하면 자동으로 /media에 마운트 됩니다.
samba 사용자 추가
samba에 사용자 pi를 추가하는 명령어입니다.
$ sudo smbpasswd -a pi
New SMB password:
Retype new SMB password:
Added user pi.
Config 파일 수정
그 후 /etc/samba/smb.conf 파일을 nano로 열어서 편집을 합니다.
이 부분은 Windows에서 연결하는 경우에만 변경해주면 됩니다.
사용자 인증 세션 부분은 다음과 같습니다.
이 부분에서 앞의 #을 제거하여 보안 설정을 활성화합니다.
그리고 파일 맨 뒤에 다음 내용을 추가합니다.
[USB]
path = /media/workspace
comment = USB File Sharing
valid users = pi
writeable = yes
browseable = yes
create mask = 0777
public = yes
파일을 저장한 다음 다음 명령어로 samba 서버를 재시작합니다.
sudo /etc/init.d/samba restart
03 Sep 2017
|
라즈베리파이
리눅스
VNC를 통한 라즈베리 원격 제어
VNC(Virtual Network Connection)를 이용하면 라즈베리파이를 원격에서 GUI 환경에서 쉽게 제어할 수 있습니다.
VNC 서버 설치
VNC(Virtual Network Connection) 서버는 다음 명령어를 이용해서 설치할 수 있습니다.
$ sudo apt-get update
$ sudo apt-get install tightvncserver
VNC 서버 실행
VNC 서버를 설치한 후, 다음 명령어를 이용해서 VNC 서버를 실행할 수 있습니다.
VNC 서버에 접속
원격에서는 VNC 클라이언트를 설치해야 합니다. 다양한 VNC 프로그램들이 있으며, RealVNC 등을 사용할 수 있습니다.
접속할 때 IP 주소 뒤에 :1을 입력하면 화면 번호 ‘1’에 접속할 수 있습니다.
라즈베리파이 시작할 때 VNC 서버 자동 실행하기
다음 명령어를 이용해서 라즈베리파이를 시작할 때 VNC 서버를 자동으로 실행되도록 할 수 있습니다.
$ cd /home/pi
$ cd .config
$ mkdir autostart
$ cd autostart
$ nano tightvnc.desktop
그 후 tightvnc.desktop 내용에 다음을 입력합니다.
[Desktop Entry]
Type=Application
Name=TightVNC
Exec=vncserver :1
StartupNotify=false
02 Sep 2017
|
라즈베리파이
리눅스
라즈베리파이에서는 raspi-config라는 프로그램을, 나노파이에서는 npi-config라는 프로그램을 이용해서 단말기의 설정을 쉽게 변경할 수 있습니다.
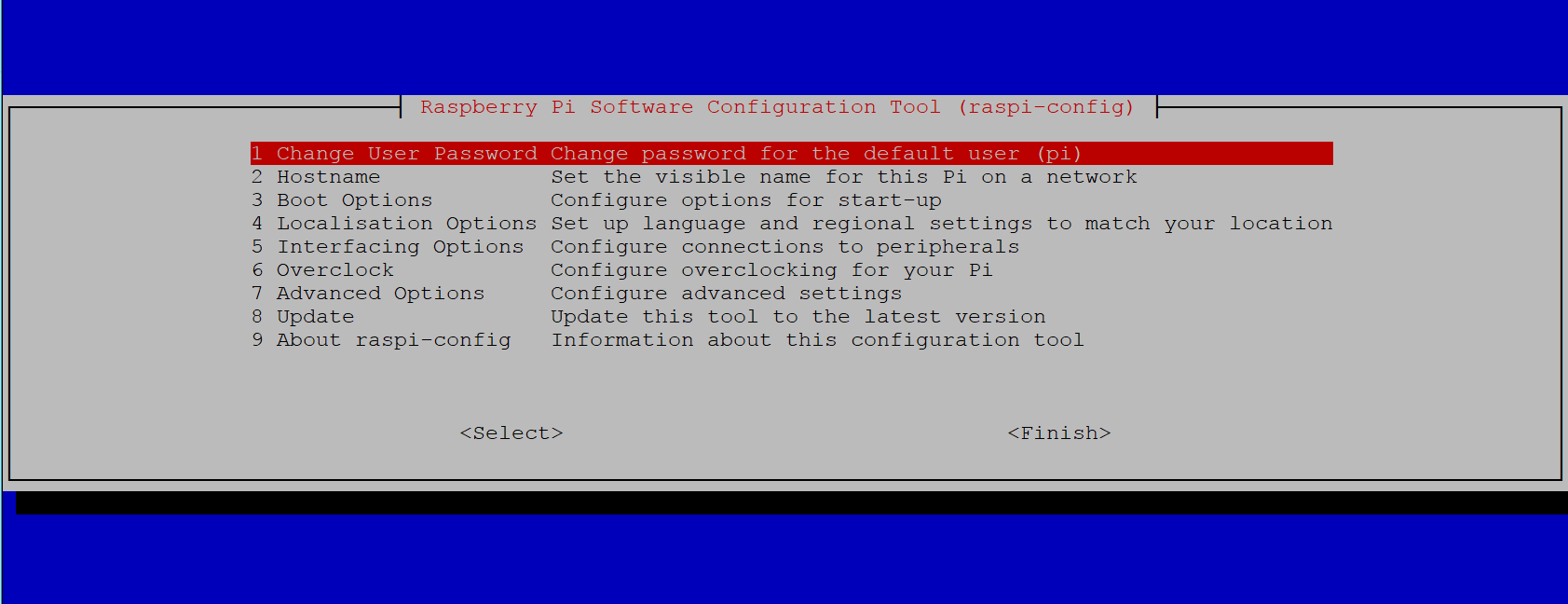
raspi-config 프로그램은 다음과 같은 기능을 제공합니다.
pi 계정의 패스워드 변경- 네트워크 호스트 이름(Hostname) 변경
- 부팅 옵션 변경
- 언어 및 지역 설정
- GPIO를 포함한 인터페이스(Interface) 설정
- 오버클럭(Overclock)
- 업데이트
- 기타 설정
raspi-config 설치 및 실행
$ sudo apt-get install raspi-config
$ sudo raspi-config
npi-config 설치 및 실행
$ sudo apt-get install npi-config
$ sudo npi-config
01 Sep 2017
|
라즈베리파이
리눅스
일반적으로 라즈베리파이는 GUI 환경이 있어서 GUI 상에서 설정을 하면 편리하지만, 나노파이(NanoPI) 또는 라즈베리파이의 non-GUI 버전을 사용할 경우에는 터미널 상에서 네트워크 세팅을 해주어야 합니다.
다음과 같이 파일을 설정하면 됩니다.
Interface 수정
/etc/network/interfaces 파일을 열어서 다음과 같이 수정해줍니다. 파일이 없다면 생성하시면 됩니다.
auto lo
iface lo inet loopback
auto wlan0
allow-hotplug wlan0
iface wlan0 inet dhcp
wpa-conf /etc/wpa_supplicant/wpa_supplicant.conf
iface default inet dhcp
SSID 정보 입력
/etc/wpa_supplicant/wpa_supplicant.conf 파일을 다음과 같이 수정해줍니다.
ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev
update_config=1
network={
ssid="snowdeer_AP"
scan_ssid=1
psk="password"
key_mgmt=WPA-PSK
}
여기서 scan_ssid 항목은 공유기의 속성이 숨김으로 되어 있을 때 사용하는 옵션입니다.
설정 이후 재부팅을 하면 라즈베리파이는 자동으로 공유기에 접속되며 IP를 할당받습니다.