11 Feb 2017
|
Windows
Windows 10에서 Bash를 설치하는 방법
2016년 봄부터 윈도우 10에서 Bash를 사용할 수 있도록 제공하고 있습니다. 하지만, 아직 정식 지원은 아니며 개발자 모드를 활성화해야만 사용할 수 있습니다. 더 자세한 내용은 여기에서 확인할 수 있습니다.
Bash를 사용하기 위한 최소 사양
- Build 14316 이후
- 64 bit 운영체제
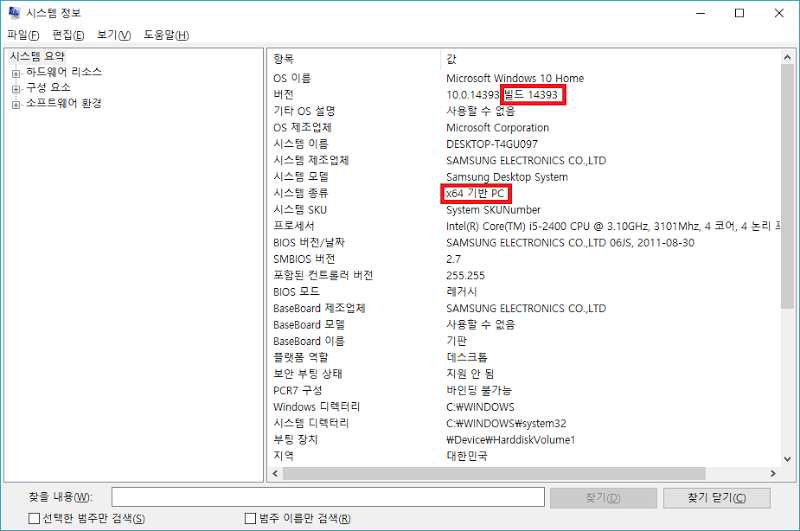
시스템 정보에서 내 PC가 요구 사양을 만족하는지 확인 할 수 있습니다.
설치 방법
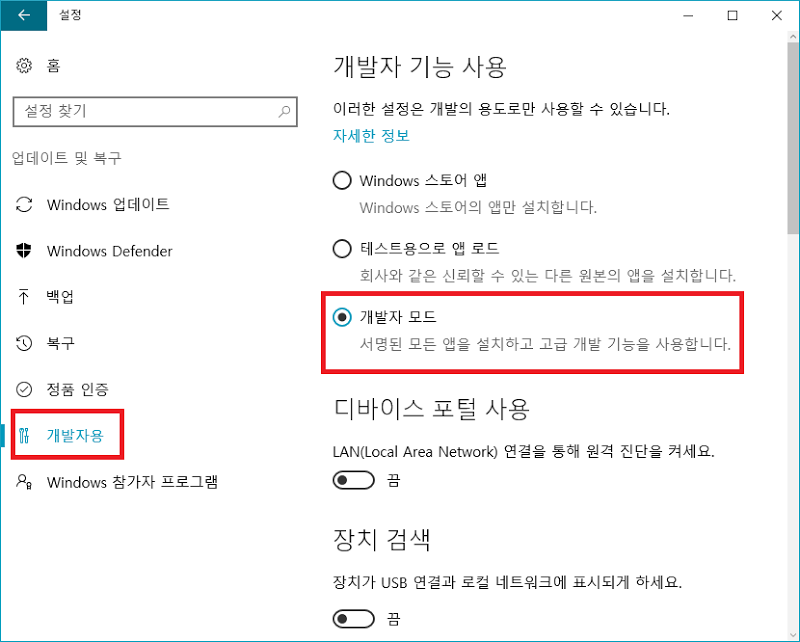
먼저 개발자 모드를 설정합니다.
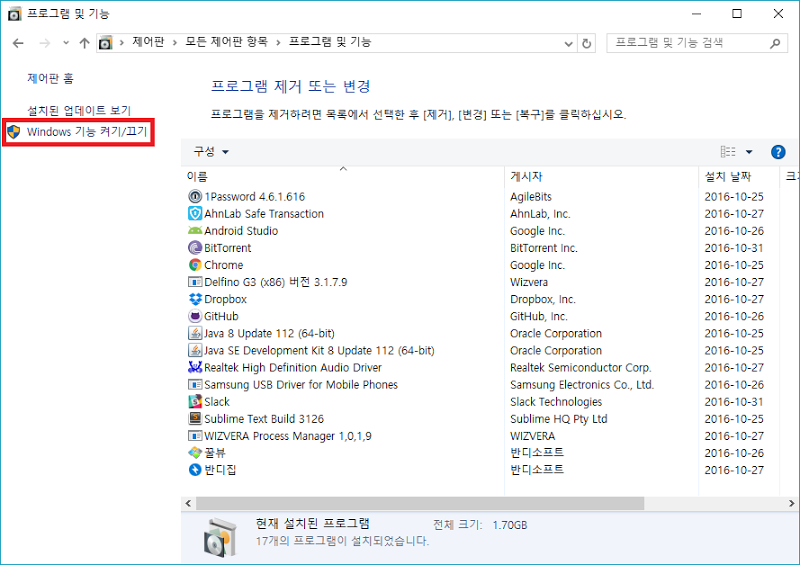
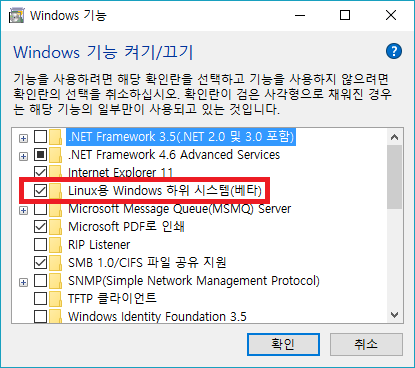
Windows 기능 켜기/끄기에서 ‘Linux용 Windows 하위 시스템(베타)’를 설치합니다.
명령 프롬프트 창에서 bash를 실행합니다.
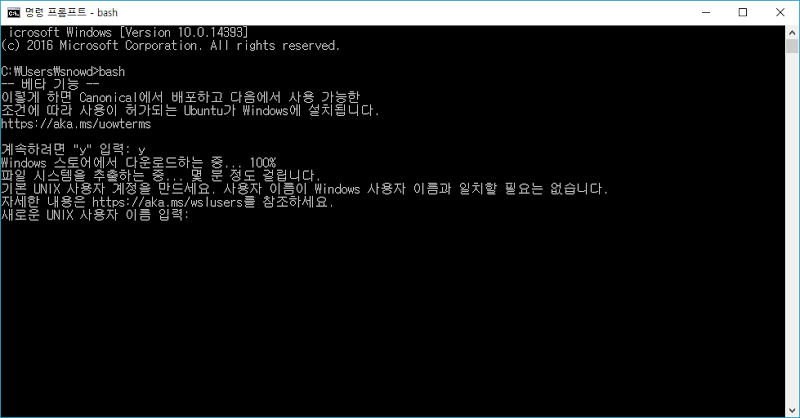
이제 bash가 설치 완료되었습니다.
30 Jan 2017
|
Android
Eclipse
IDE
문제 해결
이제는 Android Studio 만을 사용하고 있어서 거의 필요가 없는 글일 수도 있지만,
가끔씩 Eclipse를 사용해야 할 경우도 있어서(과거에 작성한 프로젝트를 수행한다거나)
포스팅을 해봅니다.
Eclipse를 사용하다가 가끔씩 Failed to create the Java Virtual Machine 오류가 뜨는 경우가 있습니다.
이런 경우는 Eclipse가 있는 폴더에 가서 eclipse.ini 파일을 수정해주면 됩니다.
(하지만, 역시 Eclipse에서 Android Studio로 갈아타는게 제일 좋은거 같습니다.)
수정 전 eclipse.ini
-startup
plugins/org.eclipse.equinox.launcher_1.3.0.v20120522-1813.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_1.1.200.v20120522-1813
-product
com.android.ide.eclipse.adt.package.product
--launcher.XXMaxPermSize
256M
-showsplash
com.android.ide.eclipse.adt.package.product
--launcher.XXMaxPermSize
256m
--launcher.defaultAction
openFile
-vmargs
-Dosgi.requiredJavaVersion=1.6
-Xms40m
-Xmx768m
-Declipse.buildId=v21.0.1-543035
수정 후 eclipse.ini
-startup
plugins/org.eclipse.equinox.launcher_1.3.0.v20120522-1813.jar
--launcher.library
plugins/org.eclipse.equinox.launcher.win32.win32.x86_1.1.200.v20120522-1813
-product
com.android.ide.eclipse.adt.package.product
--launcher.XXMaxPermSize
128M
-showsplash
com.android.ide.eclipse.adt.package.product
--launcher.XXMaxPermSize
128m
--launcher.defaultAction
openFile
-vmargs
-Dosgi.requiredJavaVersion=1.6
-Xms40m
-Xmx768m
-Declipse.buildId=v21.0.1-543035
29 Jan 2017
|
Android
Event
안드로이드에서 어플리케이션(이하 App)을 설치하거나 삭제할 때는 그 이벤트가 Broadcast로
전달됩니다. 즉, BroadcastReceiver를 등록해놓은 각 App들의 설치/삭제 이벤트를 수신할 수 있습니다.
AndroidManifest.xml
manifest.xml에 다음과 같이 BroadcastReceiver를 추가해줍니다.
<receiver android:name=".PackageEventReceiver">
<intent-filter>
<action android:name="android.intent.action.PACKAGE_ADDED"/>
<action android:name="android.intent.action.PACKAGE_REMOVED"/>
<action android:name="android.intent.action.PACKAGE_REPLACED"/>
<data android:scheme="package"/>
</intent-filter>
</receiver>
PackageEventReceiver.java
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
import android.util.Log;
public class PackageEventReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
String packageName = intent.getData().getSchemeSpecificPart();
String action = intent.getAction();
if(action.equals(Intent.ACTION_PACKAGE_ADDED)) {
Log.d("", "[snowdeer] Package ADDED : " + packageName);
} else if(action.equals(Intent.ACTION_PACKAGE_REMOVED)) {
Log.d("", "[snowdeer] Package REMOVED : " + packageName);
}
}
}
Event Receiver 등록
private PackageEventReceiver mPackageEventReceiver = new PackageEventReceiver();
private void registerPackageEventReceiver() {
registerReceiver(mPackageEventReceiver, new IntentFilter(Intent.ACTION_PACKAGE_ADDED));
}
또는 다음과 같은 코드를 이용해서 등록하면 됩니다.
private PackageEventReceiver mPackageEventReceiver = new PackageEventReceiver();
private void registerPackageEventReceiver() {
IntentFilter intentFilter = new IntentFilter();
intentFilter.addAction(Intent.ACTION_PACKAGE_ADDED);
intentFilter.addAction(Intent.ACTION_PACKAGE_INSTALL);
intentFilter.addDataScheme("package");
registerReceiver(mPackageEventReceiver, intentFilter);
}
27 Jan 2017
|
Android
UX
Open Source
일반적인 AppIntro 화면은 대략 다음과 같은 형태를 하고 있습니다.

많은 사람들이 사용하고 있는 오픈소스가 있으며, 여기에서 확인할
수 있습니다.
Dependency 설정
Android Studio에서는 간단히 gradle에 다음 라인만 추가하면 AppIntro 컴포넌트를 사용할 수 있습니다.
dependencies {
compile 'com.github.paolorotolo:appintro:4.1.0'
}
사용하는 코드는 다음과 같습니다. AppIntro 클래스를 상속받은 Activity를 구현하면 됩니다.
그리고 중요한 점은 onCreate() 함수 내에서 setContentView() 함수는 지워야 한다는 점입니다.
각각의 Intro 화면들은 Fragment를 상속받아서 구현할 수 있습니다.
SplashActivity.java
import android.content.Intent;
import android.os.Build;
import android.support.annotation.Nullable;
import android.support.v4.app.Fragment;
import android.os.Bundle;
import android.view.Window;
import android.view.WindowManager;
import com.github.paolorotolo.appintro.AppIntro;
public class SplashActivity extends AppIntro {
Fragment mSplash1 = new SplashFragment1();
Fragment mSplash2 = new SplashFragment2();
Fragment mSplash3 = new SplashFragment3();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
//setContentView(R.layout.activity_splash);
if(Build.VERSION.SDK_INT >= Build.VERSION_CODES.KITKAT) {
Window w = getWindow(); // in Activity's onCreate() for instance
w.setFlags(WindowManager.LayoutParams.FLAG_LAYOUT_NO_LIMITS,
WindowManager.LayoutParams.FLAG_LAYOUT_NO_LIMITS);
}
addSlide(mSplash1);
addSlide(mSplash2);
addSlide(mSplash3);
}
@Override
public void onSkipPressed(Fragment currentFragment) {
super.onSkipPressed(currentFragment);
startMainActivity();
}
@Override
public void onDonePressed(Fragment currentFragment) {
super.onDonePressed(currentFragment);
startMainActivity();
}
@Override
public void onSlideChanged(@Nullable Fragment oldFragment,
@Nullable Fragment newFragment) {
super.onSlideChanged(oldFragment, newFragment);
}
@Override
protected void onResume() {
super.onResume();
}
private void startMainActivity() {
Intent intent = new Intent(SplashActivity.this, MainActivity.class);
startActivity(intent);
finish();
}
}
26 Jan 2017
|
Android
UX
Open Source
Ken Burns Effect는
패닝(Panning)과 줌(Zooming) 기반으로 사진을 화려하게 보여줄 수 있는 효과(Effect)로
사진으로부터 동영상 등을 뽑아낼 때 많이 사용하고 있습니다.
Ken Burns Effect의 모습은 다음과 같습니다.

이미 아주 많은 사람들이 사용하고 있는 오픈소스가 있으니 그걸 활용하도록 하겠습니다.
여기에서 소스 코드를 확인할 수 있으며,
Android Studio에서는 간단히 gradle에 다음 라인만 추가하면 KenBurnsView를 사용할 수 있습니다.
Dependency 설정
dependencies {
compile 'com.flaviofaria:kenburnsview:1.0.7'
}
Layout 코드
실제로 사용할 때는 다음과 같이 XML에 KenburnsView를 배치하기만 하면 됩니다.
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/activity_main"
android:layout_width="match_parent"
android:layout_height="match_parent">
<com.flaviofaria.kenburnsview.KenBurnsView
android:id="@+id/image"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:src="@drawable/image" />
</RelativeLayout>
특별히 Java 코드를 따로 추가하지 않더라도 훌륭한 Ken Burns 효과를 보여주며, Java 코드를 통해 좀 더 다양하고 정교한 동작을 설정할 수 있습니다.