20 Jun 2026
|
claude
vscode에서 bypass 모드 설정하기
vscode settings
먼저 세팅에서 아래 설정을 켜야 함
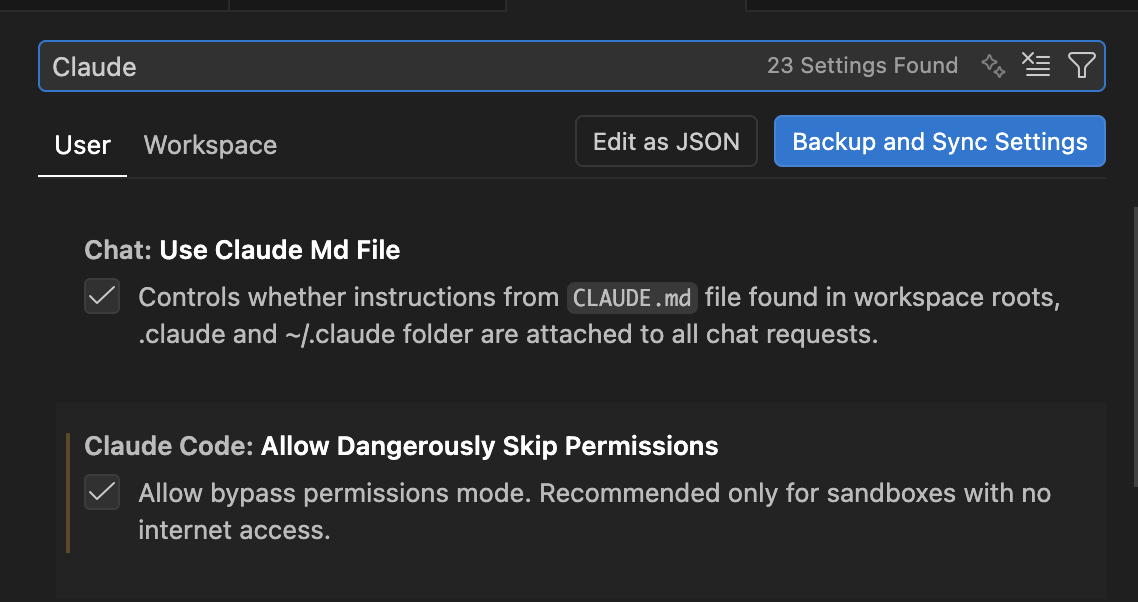
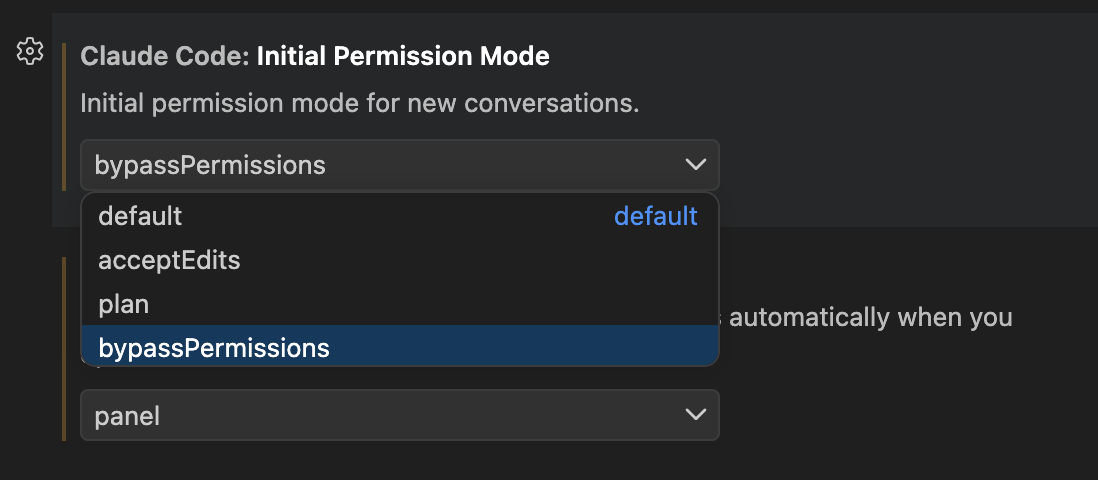
claude/settings.json
프로젝트 루트에 claude/settings.json
{
"permissions": {
"allow": ["Bash", "Read"],
"deny": [],
"defaultMode": "bypassPermissions"
}
}
완전히 격리된 환경(컨테이너, VM, CI 등)이 아닌 경우 bypassPermissions 모드 사용에 주의가 필요함.
적용 확인

13 Jun 2026
|
claude
spec-kit 예제 (작은 규모의 Task 명세)
처음부터 너무 큰 규모의 프로젝트를 만드려고 하면 명세가 너무 방대해져서
비효율적이 됨
전체를 한 번에 명세하는 않는 것이 중요함
기본 전략: Epic -> Feature 단위로 쪼개기
전체 프로젝트 (너무 큼 ❌)
↓
Epic 단위로 분리
↓
Feature 단위로 spec-kit 실행 (✅ 이 단위로)
실제 spec-kit에서도 권장하는 방식임.
specify init 할 때 프로젝트 전체가 아닌 기능 단위 브랜치에서 실행하는게 기본 사용법
구체적인 운영 방법
1. Constitution만 전체 프로젝트 기준으로 한 번 작성
/speckit.constitution
# 이것만 프로젝트 전체 기준으로 작성
- 기술 스택, 코딩 컨벤션, 아키텍처 원칙
- 한 번 쓰고 거의 수정 안 함
2. 나머지는 기능 브랜치마다 반복
bash# 기능마다 브랜치 따고
git checkout -b feature/todo-auth
# 그 기능만 명세
/speckit.specify # 이 기능에서 뭘 만들지만
/speckit.plan # 이 기능의 기술 계획만
/speckit.tasks # 이 기능의 태스크만
/speckit.implement
3. Specify는 딱 한 기능만 기술
# ❌ 이렇게 하지 말 것
"로그인, 회원가입, 대시보드, 알림, 결제, 관리자 페이지 만들어줘"
# ✅ 이렇게
"이번 브랜치에서는 이메일/비밀번호 로그인 기능만.
- 로그인 폼 UI
- JWT 토큰 저장
- 로그인 실패 에러 처리
이것만 구현"
프로젝트 규모별 권장 단위
| 규모 |
브랜치 하나에 담을 범위 |
| 소규모 |
화면 하나 (예: 로그인 페이지) |
| 중규모 |
도메인 하나 (예: 인증 전체) |
| 대규모 |
마이크로서비스 하나 |
결국 spec-kit을 프로젝트 전체 설계 도구가 아니라 기능 단위 실행 도구로 쓰는 게 핵심
앞서 개발했던 LeRobot Dataset Visualization Task 쪼개기
분리 기준
| 기능 |
설명 |
| Feature 1 |
프로젝트 기반 셋업 |
| Feature 2 |
HuggingFace Dataset 다운로드 |
| Feature 3 |
로컬 Dataset & Episode 탐색 |
| Feature 4 |
Episode 뷰어 (영상 + 차트 + 재생) |
Feature 1: 프로젝트 기반 셋업
/speckit.specify
백엔드(FastAPI)와 프론트엔드(Vue3) 프로젝트 기본 골격을 구성해줘.
## 요구사항
- 백엔드: uv 기반 FastAPI 프로젝트 초기화
- /health 엔드포인트 (서버 상태 확인용)
- datasets/ 디렉토리 자동 생성
- CORS 설정 (Vue 개발 서버 허용)
- 프론트엔드: Vue3 + TypeScript 프로젝트 초기화
- axios 또는 fetch 기반 API 클라이언트 설정
- 기본 레이아웃 컴포넌트 (사이드바 + 메인 영역)
- LeRobot Dataset v3.0 지원
Feature 2: HuggingFace Dataset 다운로드
/speckit.specify
HuggingFace에서 LeRobot dataset을 검색하고 로컬에 다운로드하는 기능을 구현해줘.
## 요구사항
- 백엔드
- LeRobot 공식 라이브러리로 HuggingFace LeRobot dataset 리스트 조회 API
- 선택한 dataset을 백엔드 datasets/ 디렉토리에 다운로드하는 API
- 다운로드 진행 상태 반환 (진행률 or 완료 여부)
- 프론트엔드
- HuggingFace dataset 리스트 출력 및 선택 UI
- 다운로드 버튼 및 진행 상태 표시
## 의존성
- Feature 1 (프로젝트 셋업) 완료 후 진행
Feature 3: 로컬 Dataset & Episode 탐색
/speckit.specify
로컬에 저장된 dataset 목록과 그 안의 episode를 탐색하는 기능을 구현해줘.
## 요구사항
- 백엔드
- datasets/ 디렉토리 내 저장된 dataset 리스트 반환 API
- 선택한 dataset 내 episode 리스트 반환 API
- 프론트엔드
- 저장된 dataset 리스트 출력 및 선택 UI
- 선택한 dataset의 episode 리스트 출력 및 선택 UI
## 의존성
- Feature 1 (프로젝트 셋업) 완료 후 진행
- Feature 2와 병렬 개발 가능
Feature 4: Episode 뷰어
/speckit.specify
선택한 episode의 영상과 센서 데이터를 동기화해서 시각화하는 기능을 구현해줘.
## 요구사항
- 백엔드
- 선택한 episode의 비디오 파일 스트리밍 API
- episode의 parquet에서 action 및 observation.state 센서 데이터 반환 API
- 프론트엔드
- 비디오 플레이어 (Play / Pause / Stop)
- 센서 데이터 시계열 차트 (비디오 아래 배치)
- 재생 시간에 따라 차트 현재 위치 동기화
## 의존성
- Feature 3 (Episode 탐색) 완료 후 진행
개발 완료 코드
- https://github.com/snowdeer/lerobot-dataset-visualization
13 Jun 2026
|
claude
spec-kit 예제 (LeRobot Dataset Visualization)
speckit-constitution
/speckit-constitution
## 프로젝트 전체의 개발 철학
- UI는 단순하고 직관적으로 유지 — 불필요한 복잡성 배제
- 직접 구현보다 검증된 라이브러리(Huggingface의 lerobot 라이브러리)를 우선 사용
- 로그인이나 인증 필요없는 PoC 서비스
- 백엔드와 프론트엔드로 구성
- 프론트엔드는 브라우저의 화면 100%의 width를 가지는 반응형 디자인
- 기술스택
- 백엔드: uv 및 Fastapi, LeRobot 공식 라이브러리 사용
- 프론트엔드: Vue3 및 TypeScript 사용

speckit-specify
/speckit-specify
다음 기능을 포함하는 웹 기반 LeRobot dataset visualization 어플리케이션 개발해줘.
## 기능 요구사항
- Dataset 다운로드 기능
- Huggingface의 LeRobot dataset 리스트 출력 및 선택
- 선택한 Huggingface LeRobot Dataset 다운로드해서 백엔드의 datasets 디렉토리 내에 저장
- Dataset 리스트 출력 및 선택 기능
- 저장된 Dataset 리스트 출력 및 선택
- 선택한 Dataset 내 Episode 리스트 출력 및 선택
- 선택한 Episode의 데이터 출력
- Dataset 내부의 비디오 영상 배치
- 그 아래 data 내부의 parquet의 센서 데이터(action 및 observation.state)를 시계열 차트 형태로 출력
- Play, Pause, Stop 기능
- LeRobot Dataset v3.0 지원
## 기술 스택
- 백엔드: uv 및 Fastapi, LeRobot 공식 라이브러리 사용
- 프론트엔드: Vue3 및 TypeScript 사용

speckit-plan
/speckit-plan
## 기술 계획 작성
요구사항을 바탕으로 Todo 앱의 기술 계획을 작성해주세요.
다음 내용을 포함해주세요:
- 백엔드, 프론트엔드의 각각의 파일 구조
- LeRobot 데이터 구조(에피소드 구분, 카메라, action, observation.state 등)
- Parquet 스트리밍 서버 구조
- 백엔드와 프론트엔드간 데이터 요청 및 전송 API
- 프론트엔드의 스켈레톤 UX 구조

speckit-tasks
/speckit-tasks
계획을 작고 실행 가능한 태스크 단위로 분해해주세요.
의존성 순서대로 정렬해주세요 (먼저 해야 할 것부터).
태스크 형식 예시:
- [ ] 백엔드, 프론트엔드의 기본 디렉토리 구조 생성
- [ ] 프론트엔드의 기본 스타일 및 CSS 작성
- [ ] 백엔드의 Huggingface LeRobot Dataset 리스트 획득 기능
- [ ] 프론트엔드의 Huggingface LeRobot Dataset 리스트 출력 및 다운로드 화면
- [ ] 백엔드의 Huggingface LeRobot Dataset 다운로드 기능
- [ ] 프론트엔드의 현재 다운로드된 LeRobot Dataset 리스트 조회 화면
- [ ] 선택한 Dataset의 episode 리스트 출력
- [ ] 선택한 episode의 데이터 상세 출력 페이지
- [ ] action 및 observation.state 값을 시계열(x축: 시간, y축: 값) 차트로 출력
- [ ] 재생시 차트에 붉은색 timeline 출력
- [ ] 재생 시 멀티 비디오 및 차트의 동기화

speckit-implement
/speckit-implement
태스크 목록의 모든 항목을 코드로 구현해주세요.
원칙(constitution)과 요구사항(spec)을 엄격히 따라주세요.
구현 가이드라인:
- 백엔드, 프론트엔드 각각 디렉토리로 구분
- 백엔드: uv 및 Fastapi 활용
- 프론트엔드: Vue3 및 TypeScript 활용

이 상태에서 완벽히 동작하는 코드가 나오지는 않음
테스트를 계속하면서 올바르게 동작하는 코드를 만들어가야 함
이러한 문제를 해결하기 위해서 spec-kit을 더 잘 활용할 수 있는 방법은 다음 포스팅에서 진행