머신 러닝(Machine Learning) 알고리즘들
03 Sep 2016 | 머신러닝Machine Learning 알고리즘들에 대해서 알아보도록 하겠습니다.
여기서는 몇 가지 대표적인 알고리즘들의 간단한 소개만 포스팅하도록 하겠습니다. 좀 더 자세한 정보를 원하시는 분들은
와 같은 사이트를 참조하시면 좀 더 다양하고 자세하게 알 수 있습니다.
Linear Regression
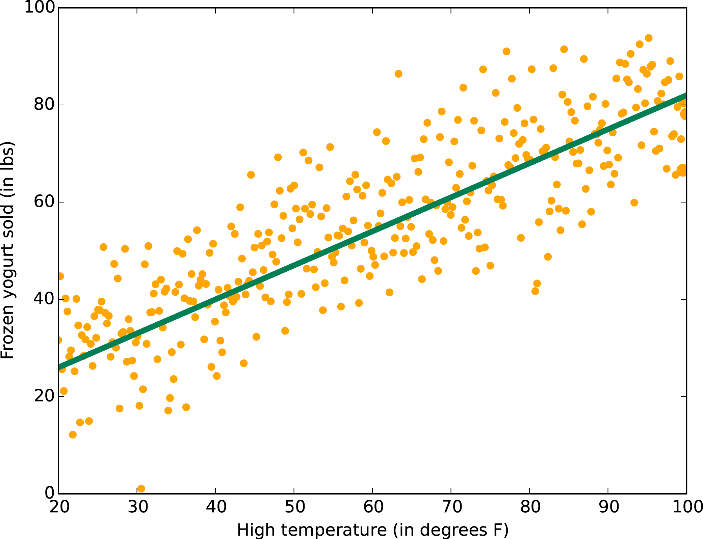
선형 회귀라고도 불리는 Linear Regression은 위의 그림과 같이 모든 데이터들이 선형적인 분포 형태를 갖고 있다는 가정으로부터 시작하는 알고리즘입니다. 자주 사용되고, 비교적 간단한 구조로 되어 있어 속도도 빠르지만 데이터들이 선형 분포를 이루는 경우가 그리 많지 않기에 정확도면에서는 떨어질 수 밖에 없는 형태입니다.
Logistic Regression
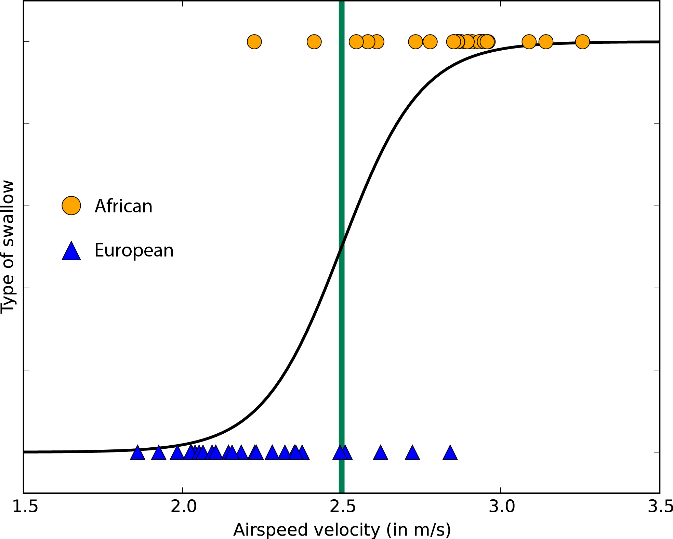
Logistic Regression는 위에서 언급한 Linear Regression이 가진 문제 때문에 나타난 알고리즘입니다. 모든 데이터가 선형 특성을 가지는게 아니기 때문에 여러 개의 클래스를 가진 Logistic Regression이 등장하게 되었고, 위 이미지는 2개의 클래스를 가진 Logistic Regression 알고리즘 예시입니다.
Trees, forests, and jungles
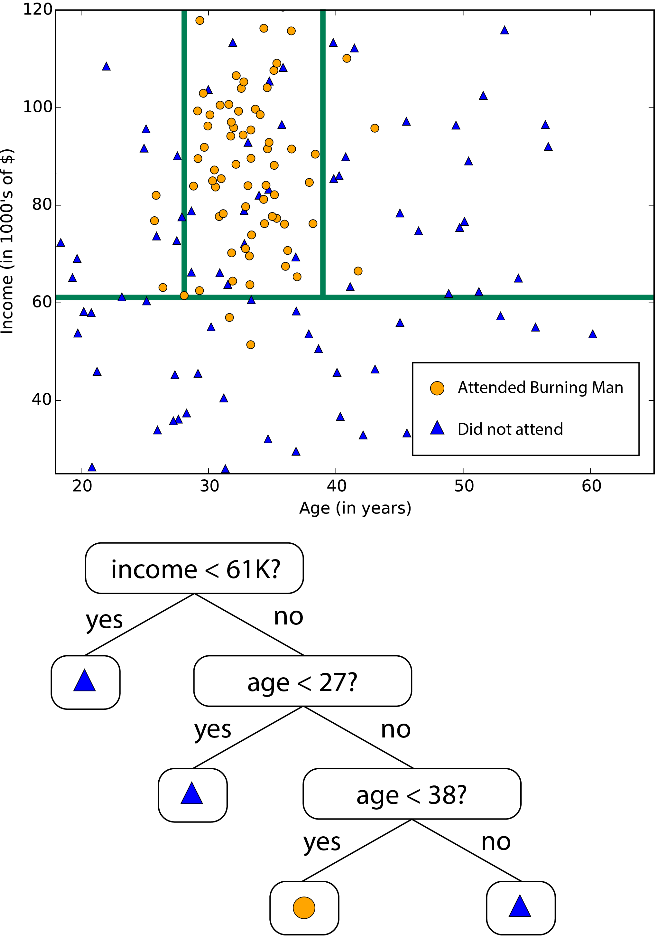
‘결정 트리’라고 해서 많이 알려진 Decision Tree나, Decision Forest, Decision Jungle이다. 전체 영역을 같은 레이블(label)을 갖는 데이터들의 영역들로 나누어 관리하는 알고리즘입니다.
- Decision Forests는 많은 양의 메모리를 필요로 합니다.
- Decision Jungle은 메모리 소모는 줄어들지만, 학습 시간이 오래 걸립니다.
Neural Networks
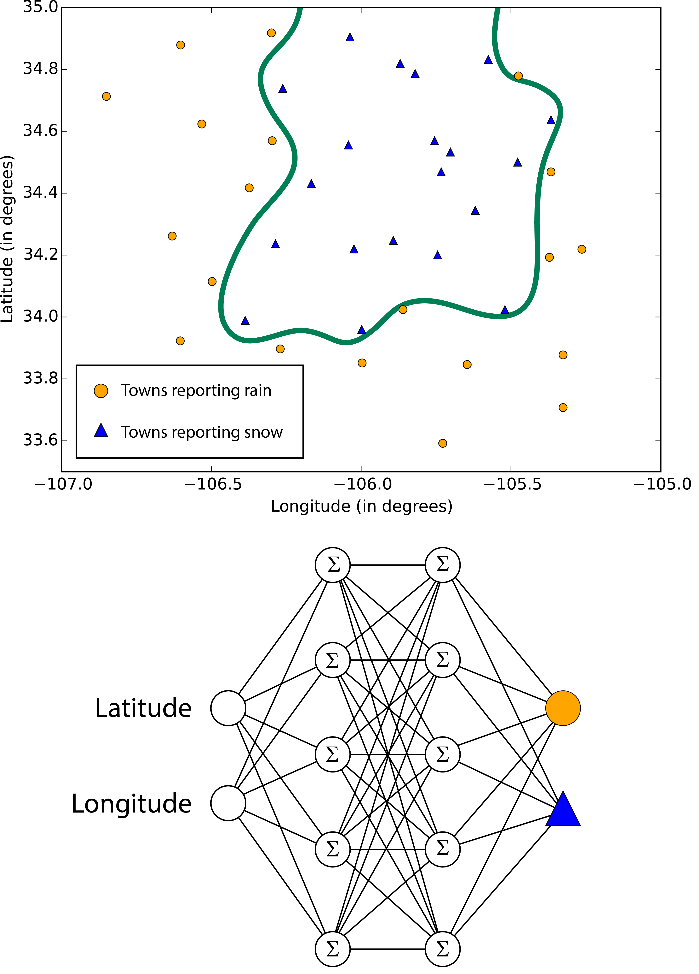
사람의 두뇌 구조에서 영감을 얻어서 만들어진 학습 기술입니다. 무제한적인 다양성을 갖게 해주지만, 상당히 복잡하고 필요로 하는 Cost 또한 높은 단점이 있습니다. 학습 시간도 오래 걸리며, 다른 알고리즘들에 비해 필요로 하는 파라메터(parameter)도 많아서 사용하기 어려운 점이 있지만, 잠재력은 무궁무진하다고 볼 수 있습니다.
Support Vector Machine
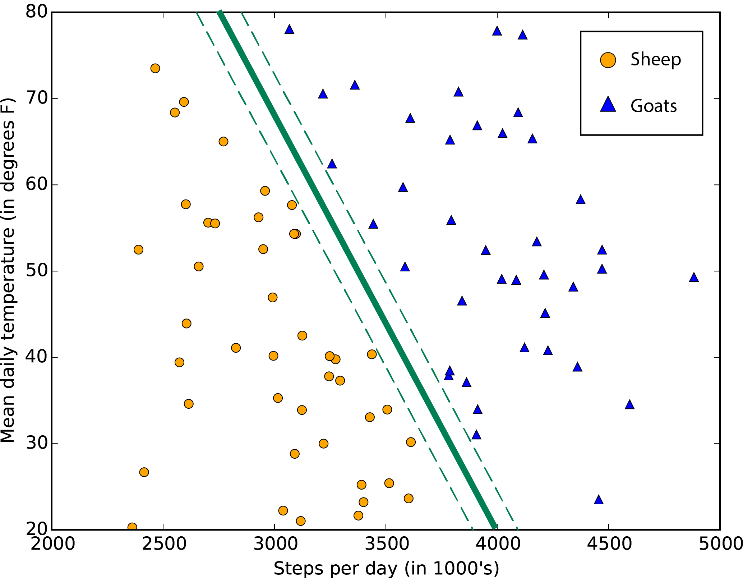
각 데이터를 구분하는 경계를 찾는 방식입니다. 경계는 위의 그림과 같이 선형으로 구할 수도 있고, 비선형으로 구할 수도 있습니다.
K-means Algorithm
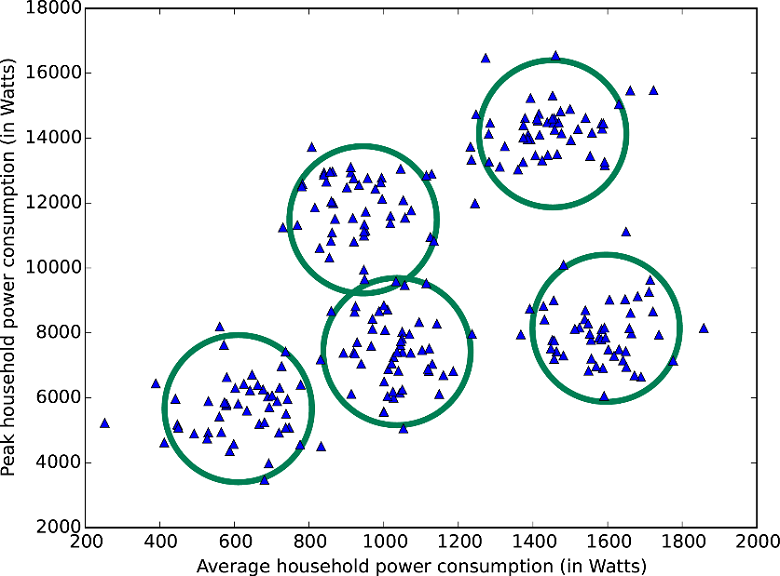
주어진 데이터들을 K 개의 클러스터(Cluster)로 나누는 알고리즘입니다. 데이터들의 거리를 기반으로 가까운 데이터들끼리 군집(Group)화 하면서 클러스터를 나눕니다. 간단히 사용하기에 괜찮은 알고리즘이긴 하지만 다음과 같은 한계점을 있습니다.
- 파라메터 K 값에 따라 그 결과가 완전히 달라집니다.
- 이상값(outlier)에 따라 중심값이 크게 왜곡될 수 있습니다.
- 구형(spherical) 데이터가 아닌 경우 적절하지 않은 상황이 발생할 수 있습니다.