머신러닝 & 딥러닝 용어 정리
04 Jan 2018 | 머신러닝인공지능, 머신러닝, 딥러닝
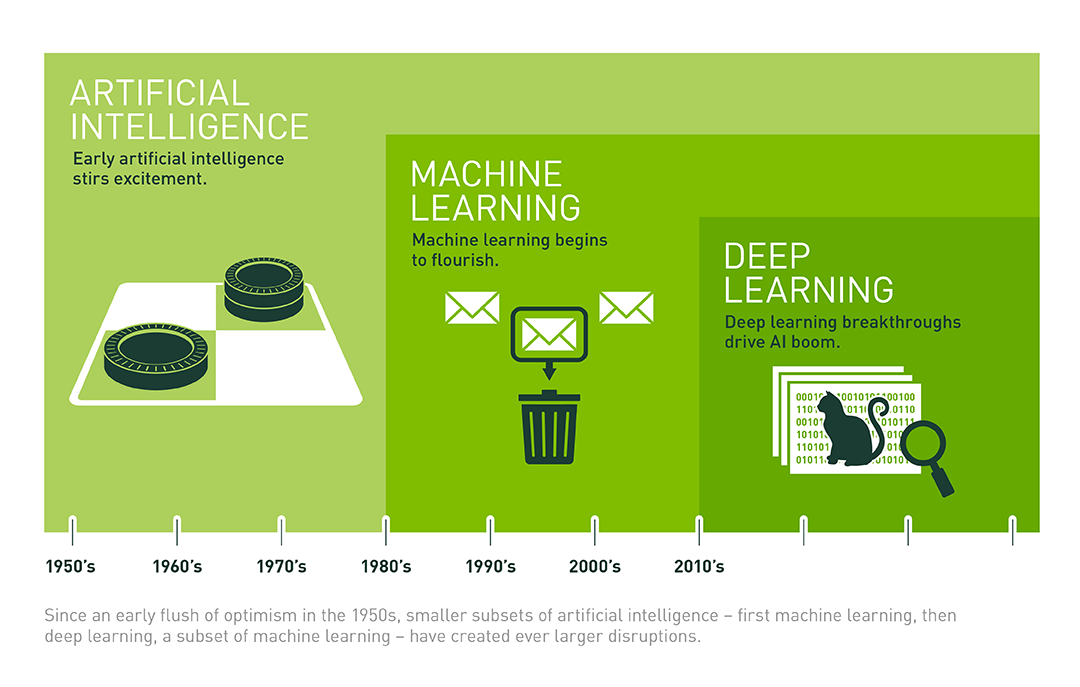
위 그림처럼 딥러닝은 머신러닝의 한 종류이며, 머신러닝은 인공지능의 한 종류입니다.
모델
머신러닝은 간단히 ‘데이터를 이용한 모델링 기법’이라고 표현할 수 있습니다. 다시 말하면, 데이터들 중에서 ‘모델’을 뽑아내는 기법입니다. 모델은 머신러닝을 통해 얻을 수 있는 최종 결과물을 의미합니다. 예를 들어, 스팸을 분리해내는 시스템을 만들었다면 해당 시스템이 ‘모델’에 해당합니다.
모델은 ‘가설(Hypothesis)’이라고도 부릅니다.
과적합(Overfitting)
Overfitting은 머신러닝에 자주 등장하는 용어입니다. 학습 데이터에 너무 최적화를 하다보니, 실제 데이터와 차이가 많이 발생하는 모델을 만들게 되는 현상을 의미합니다. 학습 데이터에도 Noise 등이 섞인 데이터들이 섞여 있을 수 있기 때문에 Overfitting을 방지하는 기법들을 적용해야 더 좋은 결과물이 나올 수 있습니다.
반대되는 경우로 Underfitting이 있습니다.
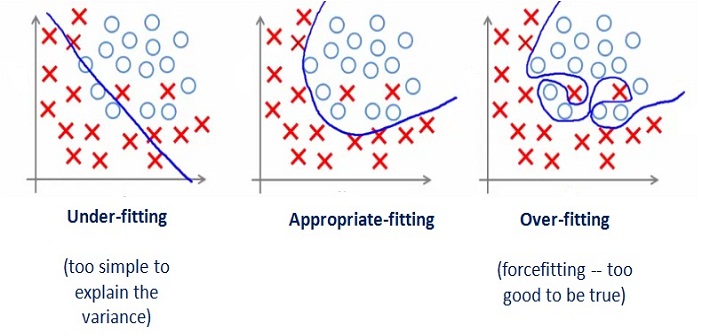
위 그림과 같이 Underfitting이 되면 너무 느슨한 모델이 만들어지게 되고, Overfitting이 발생하면 너무 과한 모델이 만들어지게 됩니다.
Regularization, Validation
머신러닝은 학습 데이터가 많을수록 더 정교한 모델을 만들어낼 수 있습니다. 하지만 Noise와 같이 일반적이지 않은 학습 데이터가 많이 섞여 있을 경우 Overfitting이 발생할 수 있습니다.
Regularization은 학습 데이터를 조금 희생하더라도 모델을 최대한 간단하게 만들어서 Overfitting을 방지하는 기법입니다.
하지만 Regularization은 눈으로 보고 쉽게 확인할 수 있지 않기 때문에 학습 과정에서의 Overfitting 여부를 판단하기가 쉽지 않습니다. 그래서 Overfitting 여부를 손쉽게 판단하기 위해서 ‘검증(Validation)’ 기법을 적용합니다.
검증용 데이터는 학습용 데이터에는 포함시키지 않고, 모델의 성능 검증에만 사용합니다.
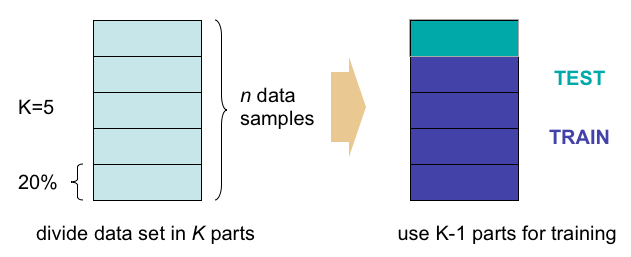
위 그림과 같이 학습 데이터의 일부(보통 80%는 학습용, 20%는 검증용)를 떼어내서 검증용으로 사용합니다.
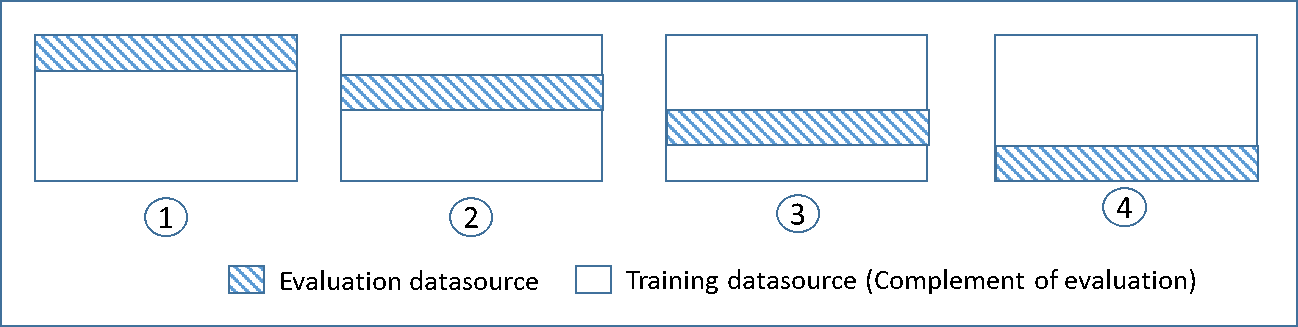
그리고 아래 이미지와 같이 검증용 데이터를 고정하지 않고 무작위로 바꿔가면서 사용하는 ‘교차검증(Cross Validation)’ 기법도 있습니다.
분류(Classification), 회귀(Regression)
분류와 회귀는 비슷하면서도 약간의 차이가 있는 용어입니다. 둘다 입력데이터로 {입력, 정답}의 형태를 가집니다. 하지만 분류의 경우 정답은 ‘범주’의 형태가 되고, 회귀의 경우 정답은 ‘값’의 형태가 된다는 차이가 있습니다.
분류와 회귀 둘 다 지도 학습(Supervised Learning)에 해당하며, 비지도 학습(Unsupervised Learning)의 ‘군집화(Clustering)’과 헷갈리는 경우가 있는데 서로 차이가 있기 때문에 구분을 해야 합니다. 참고로, 군집화는 비슷한 데이터들끼리 묶어주는 기능입니다.

신경망
신경망(Neural Network)는 사람의 두뇌 모양을 흉내내서 만든 모델로 수많은 노드들과 각 노드들간의 가중치로 이루어져 있습니다.
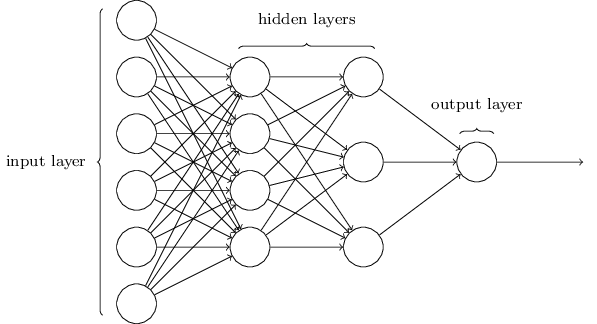
학습 데이터를 이용해서 학습을 하면서 그 결과값에 따라 각 노드들간의 가중치를 조금씩 바꿔가는 학습 방법입니다.
델타 규칙
델타 규칙은 Adaline, Widrow-Hoff 규칙이라고도 하며, 주어진 정보에 따라 단층 신경망의 가중치를 체계적으로 바꾸어주는 규칙입니다.
어떤 output 노드에서 오차가 발생했다면, output 노드와 input 노드간 연결 가중치는 input 노드의 출력과 output 노드의 오차에 비례해서 조절한다.
델타 규칙을 수식으로 표현하면 다음과 같습니다.
\[w_ij ← w_ij + α e_i x_j \\ \Delta w_ij = α e_i x_j\]단순히 생각하면 오차가 크면 가중치를 많이 조절하고, 오차가 작으면 가중치를 적게 조절하는거라고 생각하면 됩니다.
여기서 α는 학습률을 의미하며 0보다 크고 1보다 작거나 같은 값을 가집니다. 학습률이 너무 높으면 정답 근처에서 수렴을 못하는 경우가 발생할 수 있고, 너무 낮으면 학습 속도가 아주 느릴 수 있습니다.
재학습 및 epoch
한 번 학습한 데이터라고 하더라도 전체 학습 데이터를 반복해서 학습하기도 합니다. 델타 규칙은 정답을 한 번에 바로 찾는게 아니라 반복적인 학습 과정을 통해 정답을 찾아가는 방식이기 때문입니다.
epoch는 학습 데이터를 한번씩 모두 학습시킨 횟수를 말합니다. ‘epoch = 10’이라면 학습 데이터를 총 10번씩 학습 시킨 것을 의미합니다.
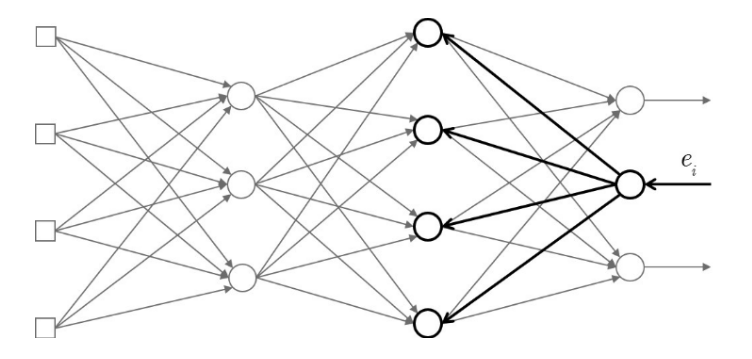
오차 역전파(Backpropagation)
델타 학습법만으로는 신경망의 모든 노드들을 학습시킬 수 없습니다. 특히 은닉(Hidden) 계층은 오차의 정의조차 되어 있지 않고, 정답 또한 정해져 있어서 학습이 불가능합니다.
1986년 오차 역전파 알고리즘이 개발되면서 학습 문제가 해결이 되었습니다. 출력층에서부터 시작해 거꾸로 추적해가며 오차에 따라 가중치를 조절하는 방법입니다.
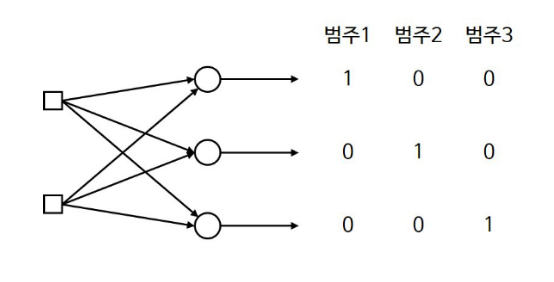
One-Hot-Encoding(1-of-N Encoding)
결과가 0과 1이 아닌, 3가지 이상의 범주를 가질 때 출력 노드를 범주 개수만큼, 그리고 각 자릿수마다 범주를 나타내도록 0과 1로 표현하는 방식을 ‘One-Hot-Encoding’이라고 합니다.

경사각 소실(Vanishing Gradient)
신경망의 계층을 깊게 할수록 성능이 더 떨어지는 원인으로 다음과 같은 이유를 들 수 있습니다.
- 경사각 소실(Vanishing Gradient)
- 과적합(Overfitting)
- 많은 계산량
활성화 함수(Activation Function)으로 많이 사용하는 시그모이드(Sigmoid) 함수는 최대 기울기가 0.3을 넘지 않습니다. 즉, 곱하면 곱할수록 0에 가까워지고 결국 0이 되는 현상이 발생해서 기울기가 사라집니다.
대안으로 시그모이드 함수대신 ReLU 함수를 사용해서 해결할 수 있습니다.