Keras - Overfitting 회피하기
09 Jan 2018 | 머신러닝 Python KerasOverfitting
과적합(Overfitting)은 머신러닝에 자주 등장하는 용어입니다. 학습 데이터에 과하게 최적화하여, 실제 새로운 데이터가 등장했을 때 잘 맞지 않는 상황을 의미합니다.
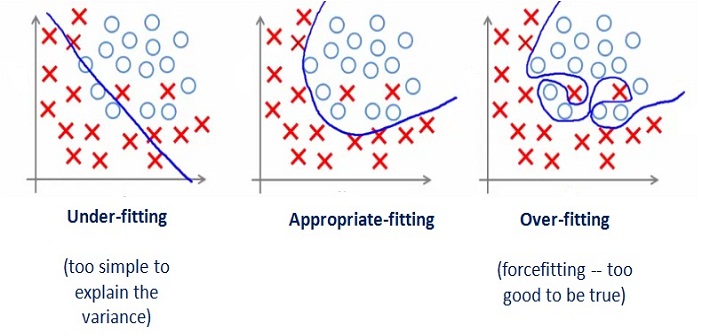
학습 데이터에도 Noise나 예외가 섞인 데이터들이 포함되어 있을 수 있고, 신경망의 층이 너무 많거나 변수가 복잡해서 Overfitting이 발생하기도 합니다.
과적합을 방지하는 건 머신러닝의 큰 숙제였고, Regularization과 Validation 등을 이용해서 과적합을 회피하는 방법들이 많이 연구되었습니다.
Regularization, Validation
Regularization은 학습 데이터를 조금 나누어서 테스트 데이터로 활용하는 방법입니다. 예를 들어 학습 데이터의 80%만 학습을 시키고, 나머지 20%는 학습을 시키지 않고 테스트에 활용하는 방법입니다. 나머지 20%로 검증을 하는 것을 Validation이라고 합니다.
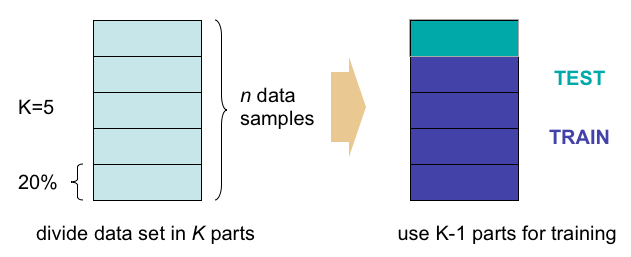
그리고 아래 이미지와 같이 검증용 데이터를 고정하지 않고 무작위로 바꿔가면서 사용하는 ‘K겹 교차검증(K-fold Cross Validation)’ 기법도 있습니다.
학습 데이터와 테스트 데이터로 분리하는 예제 코드
sklearn 모듈을 이용하면 주어진 데이터를 학습 데이터와 테스트 데이터로 쉽게 나눌 수 있습니다.
from sklearn.model_selection import train_test_split
...
# 주어진 데이터를 학습 데이터와 테스트 데이터로 분리
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y, test_size=0.2)
...
# 학습 데이터를 이용해서 학습
model.fit(X_train, Y_train, epochs=100, batch_size=5)
# 테스트 데이터를 이용해서 검증
print('\nAccuracy: %.4f' % (model.evaluate(X_validation, Y_validation)[1]))
전체 코드는 다음과 같습니다. (기존의 아이리스 품종 분류 코드에 적용했습니다.)
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
import pandas as pd
df = pd.read_csv('iris.csv',
names=["sepal_length", "sepal_width", "petal_length",
"petal_width", "species"])
data_set = df.values
X = data_set[:, 0:4].astype(float)
obj_y = data_set[:, 4]
encoder = LabelEncoder()
encoder.fit(obj_y)
Y_encodered = encoder.transform(obj_y)
Y = np_utils.to_categorical(Y_encodered)
# 주어진 데이터를 학습 데이터와 테스트 데이터로 분리
X_train, X_validation, Y_train, Y_validation = train_test_split(X, Y,
test_size=0.2)
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])
# 학습 데이터를 이용해서 학습
model.fit(X_train, Y_train, epochs=100, batch_size=5)
# 테스트 데이터를 이용해서 검증
print('\nAccuracy: {:.4f}'.format(model.evaluate(X_validation, Y_validation)[1]))
K겹 교차 검증 예제 코드
K겹 교차 검증도 sklearn 모듈을 이용해서 쉽게 적용할 수 있습니다.
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import KFold
import pandas as pd
df = pd.read_csv('iris.csv',
names=["sepal_length", "sepal_width", "petal_length",
"petal_width", "species"])
data_set = df.values
X = data_set[:, 0:4].astype(float)
obj_y = data_set[:, 4]
encoder = LabelEncoder()
encoder.fit(obj_y)
Y_encodered = encoder.transform(obj_y)
Y = np_utils.to_categorical(Y_encodered)
# 주어진 데이터를 학습 데이터와 테스트 데이터로 분리
skf = KFold(n_splits=5, shuffle=True)
accuracy = []
for train, validation in skf.split(X, Y):
model = Sequential()
model.add(Dense(16, input_dim=4, activation='relu'))
model.add(Dense(3, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam',
metrics=['accuracy'])
# 학습 데이터를 이용해서 학습
model.fit(X[train], Y[train], epochs=100, batch_size=5)
# 테스트 데이터를 이용해서 검증
k_accuracy = '%.4f' % (model.evaluate(X[validation], Y[validation])[1])
accuracy.append(k_accuracy)
# 전체 검증 결과 출력
print('\nK-fold cross validation Accuracy: {}'.format(accuracy))