Keras - 이진 데이터 분류 예제
13 Jan 2018 | 머신러닝 Python KerasKeras를 이용한 이진 데이터(Binary Data) 분류하기 예제 코드
데이터셋은 아래의 코드를 이용해서 랜덤으로 생성합니다.
import numpy as np x_train = np.random.random((1000, 12)) y_train = np.random.randint(2, size=(1000, 1)) x_test = np.random.random((100, 12)) y_test = np.random.randint(2, size=(100, 1)) import matplotlib.pyplot as plt plot_x = x_train[:, 0] plot_y = x_train[:, 1] plot_color = y_train.reshape(1000, ) plt.scatter(plot_x, plot_y, c=plot_color) plt.show()
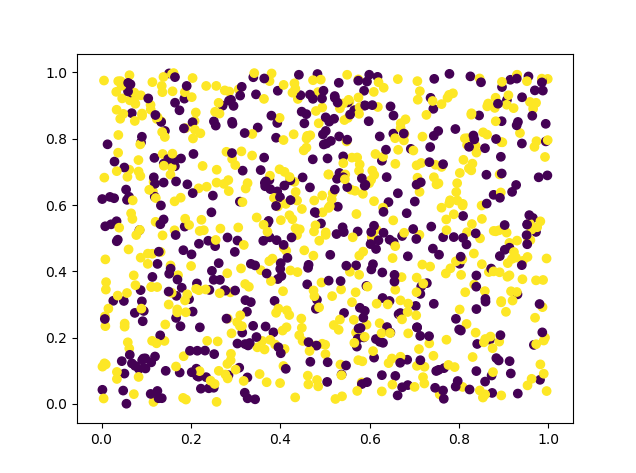
사실 위 데이터는 완전 무작위로 생성한 값이기 때문에 특정 패턴이 없습니다. 그래서 머신 러닝에서 활용하기에 그리 좋은 케이스는 아닙니다. 하지만 이런 무작위 데이터는 아주 쉽게 만들 수 있기 때문에 연습용으로 활용하거나, 실제 데이터 분석을 하기 전 프로토타입 구현용으로는 괜찮은 것 같습니다.
퍼셉트론 신경망 예제
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
x_train = np.random.random((1000, 12))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 12))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(1, input_dim=12, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
metrics=['accuracy'])
hist = model.fit(x_train, y_train, epochs=100, batch_size=30)
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.set_ylim([0.0, 1.0])
acc_ax.set_ylim([0.0, 1.0])
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
acc_ax.plot(hist.history['acc'], 'b', label='train acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=30)
print('loss_and_metric: {}'.format(loss_and_metrics))
실행 결과는 다음과 같습니다.
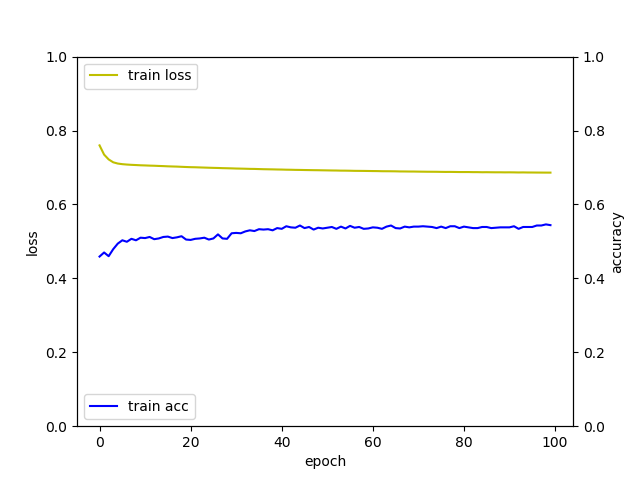
다층 퍼셉트론 신경망 예제
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
x_train = np.random.random((1000, 12))
y_train = np.random.randint(2, size=(1000, 1))
x_test = np.random.random((100, 12))
y_test = np.random.randint(2, size=(100, 1))
model = Sequential()
model.add(Dense(64, input_dim=12, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy',
metrics=['accuracy'])
hist = model.fit(x_train, y_train, epochs=100, batch_size=30)
import matplotlib.pyplot as plt
fig, loss_ax = plt.subplots()
acc_ax = loss_ax.twinx()
loss_ax.set_ylim([0.0, 1.0])
acc_ax.set_ylim([0.0, 1.0])
loss_ax.plot(hist.history['loss'], 'y', label='train loss')
acc_ax.plot(hist.history['acc'], 'b', label='train acc')
loss_ax.set_xlabel('epoch')
loss_ax.set_ylabel('loss')
acc_ax.set_ylabel('accuracy')
loss_ax.legend(loc='upper left')
acc_ax.legend(loc='lower left')
plt.show()
loss_and_metrics = model.evaluate(x_test, y_test, batch_size=30)
print('loss_and_metric: {}'.format(loss_and_metrics))
실행 결과는 다음과 같습니다.
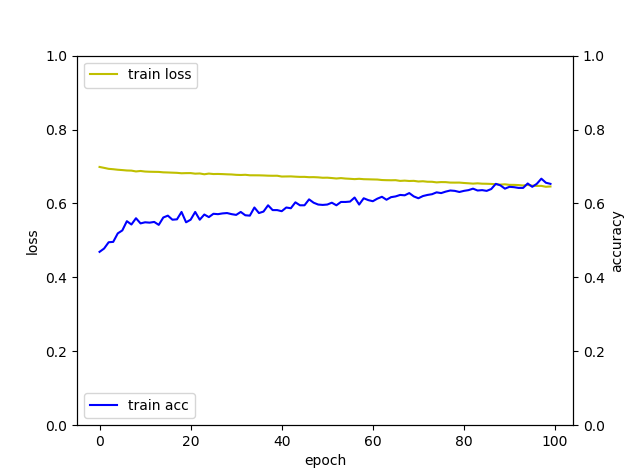
사실 데이터셋이 완전 무작위이이 때문에 많은 결론을 도출할 수는 없지만, 여기서 알 수 있는 것은 다층 신경망이 단층 신경망보다는 학습 속도가 훨씬 더 빠르다는 것을 알 수 있습니다.