25 Nov 2016
|
Android
UX
ProgressBar는 로딩 등과 같이 어떤 작업이 수행되고 있다는 것을 사용자에게 알려주기 위한
UX 컴포넌트입니다. 원형, 선형 등과 같이 다양한 형태의 ProgressBar가 존재합니다.
그리고 이러한 ProgressBar를 Dialog 형태인 ProgressDialog로도 보여줄 수 있습니다.
좀 더 자세한 정보는 여기를 참조하시면
됩니다.
예제 코드
private ProgressDialog mProgressDialog;
private void showProgressDialog(String message) {
closeProgressDialog();
mProgressDialog = new ProgressDialog(this);
mProgressDialog.setTitle("");
mProgressDialog.setMessage(message);
mProgressDialog.setCancelable(true);
mProgressDialog.setIndeterminate(true);
mProgressDialog.show();
}
private void closeProgressDialog() {
if((mProgressDialog != null) && (mProgressDialog.isShowing())) {
mProgressDialog.dismiss();
}
mProgressDialog = null;
}
24 Nov 2016
|
Android
UX
안드로이드에서 간단한 AlertDialog를 띄우는 예제 코드입니다.
좀 더 자세한 정보와 예제 코드는 여기를 참조하시면 됩니다.
예제 코드
package com.lnc.datacafe;
import android.app.Activity;
import android.content.DialogInterface;
import android.os.Bundle;
import android.support.v7.app.AlertDialog;
public class MainActivity extends Activity {
private AlertDialog mAlertDialog;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
showAlertDialog();
}
private void showAlertDialog() {
if(mAlertDialog != null) {
mAlertDialog.dismiss();
mAlertDialog = null;
}
mAlertDialog = new AlertDialog.Builder(this)
.setTitle("여기에 Title을 입력하세요.")
.setMessage("여기에 Message를 입력하세요")
.setCancelable(true)
.setPositiveButton("Ok", new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int id) {
// TODO
}
})
.setNegativeButton("Cancel", new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int id) {
dialog.cancel();
}
}).create();
mAlertDialog.show();
}
}
14 Nov 2016
|
Windows
Windows 10 - 설치할 프로그램들
개인적으로 구매해서 사용하는 프로그램들이나 실생활 또는 개발시 유용하게 사용하는 프로그램들입니다.
13 Nov 2016
|
Windows
Windows 10 - 설치 후 초반 세팅
Windows 10 초기화를 수십차례 했음에도 자꾸 잊어버리는 작업들이 있어서 메모 차원에서 간단히 정리해보았습니다. 어디까지나 제 개인적인 취향이나 설정에 치우친 글입니다.
윈도우 & 드라이버 업데이트
가장 필수적이며, 최우선으로 하도록 합시다.
에서 설정 및 최신 드라이버로 업데이트할 수 있습니다.
키보드 재입력 시간 조절
개인적으로 키보드 재입력 시간에 딜레이가 있으면 너무 답답해서 키보드 재입력 시간을 최소화 해주고 있습니다.
에서 설정할 수 있습니다.
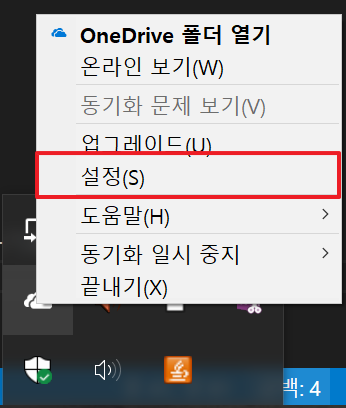
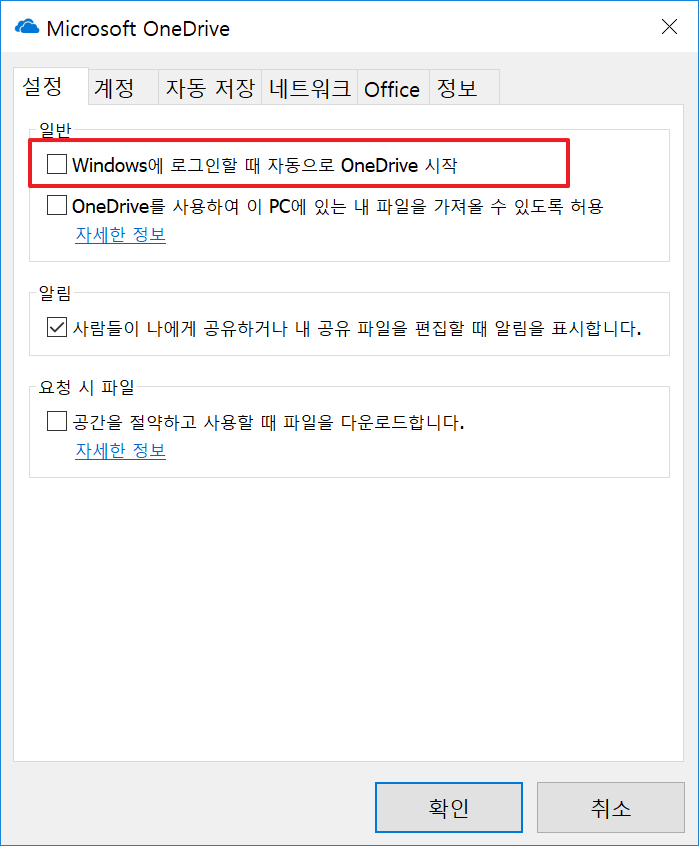
OneDrive 사용 Off
한 때 OneDrive를 많이 사용했었는데, 너무 느리기도 하고 동기화로 인한 LTE 데이터 소진 등을 막기 위해서 요즘은 아예 끄고 다닙니다.
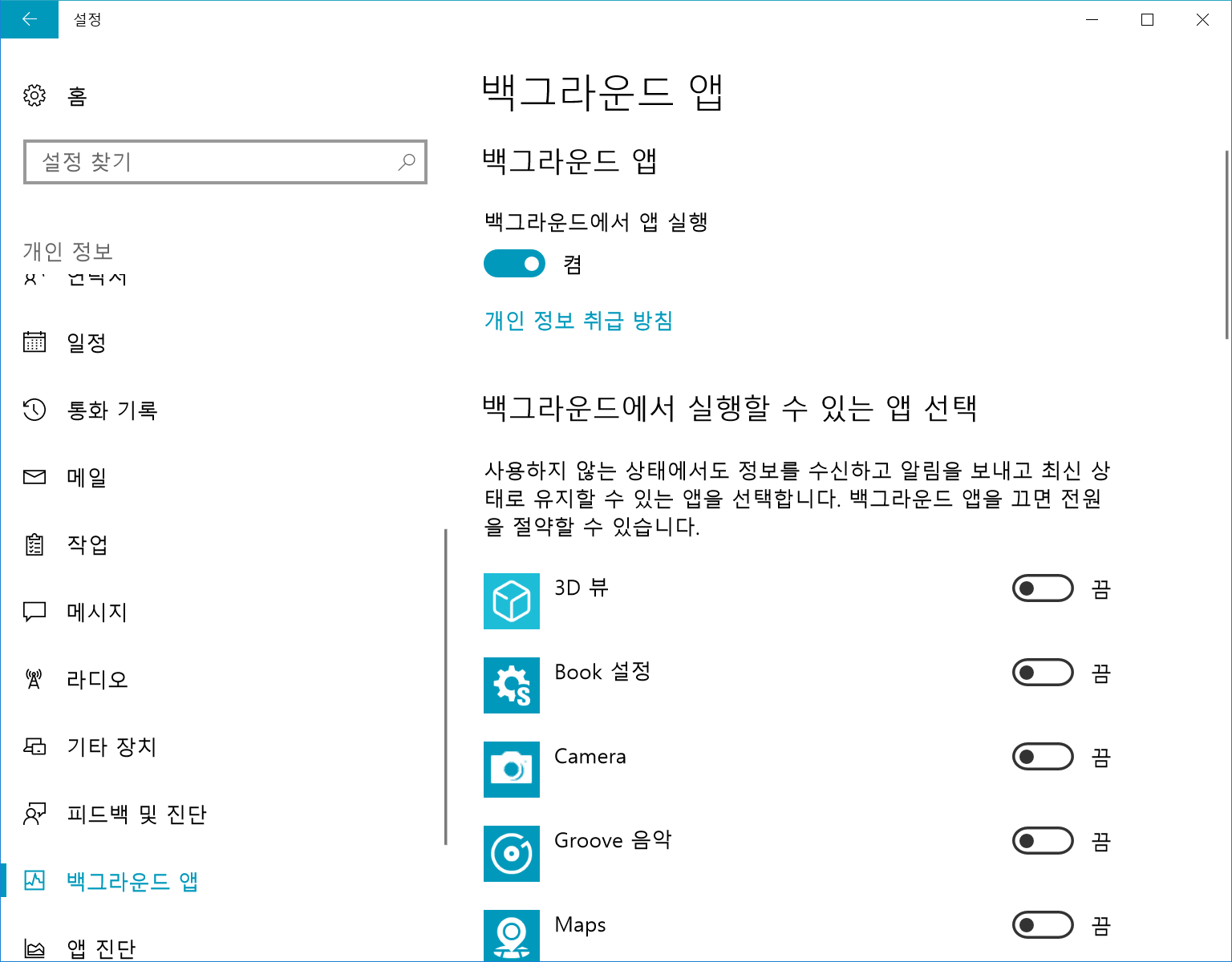
백그라운드 앱 Off
백그라운드 어플이 돌아가면 아무래도 CPU나 배터리 소모, 데이터 사용량이 증가할 수 밖에 없습니다. 꼭 필요한 서비스들(ex. 날씨 등)만 제외하고는 전부 Off로 하는 것이 좋습니다.
스토어 앱 추천 Off
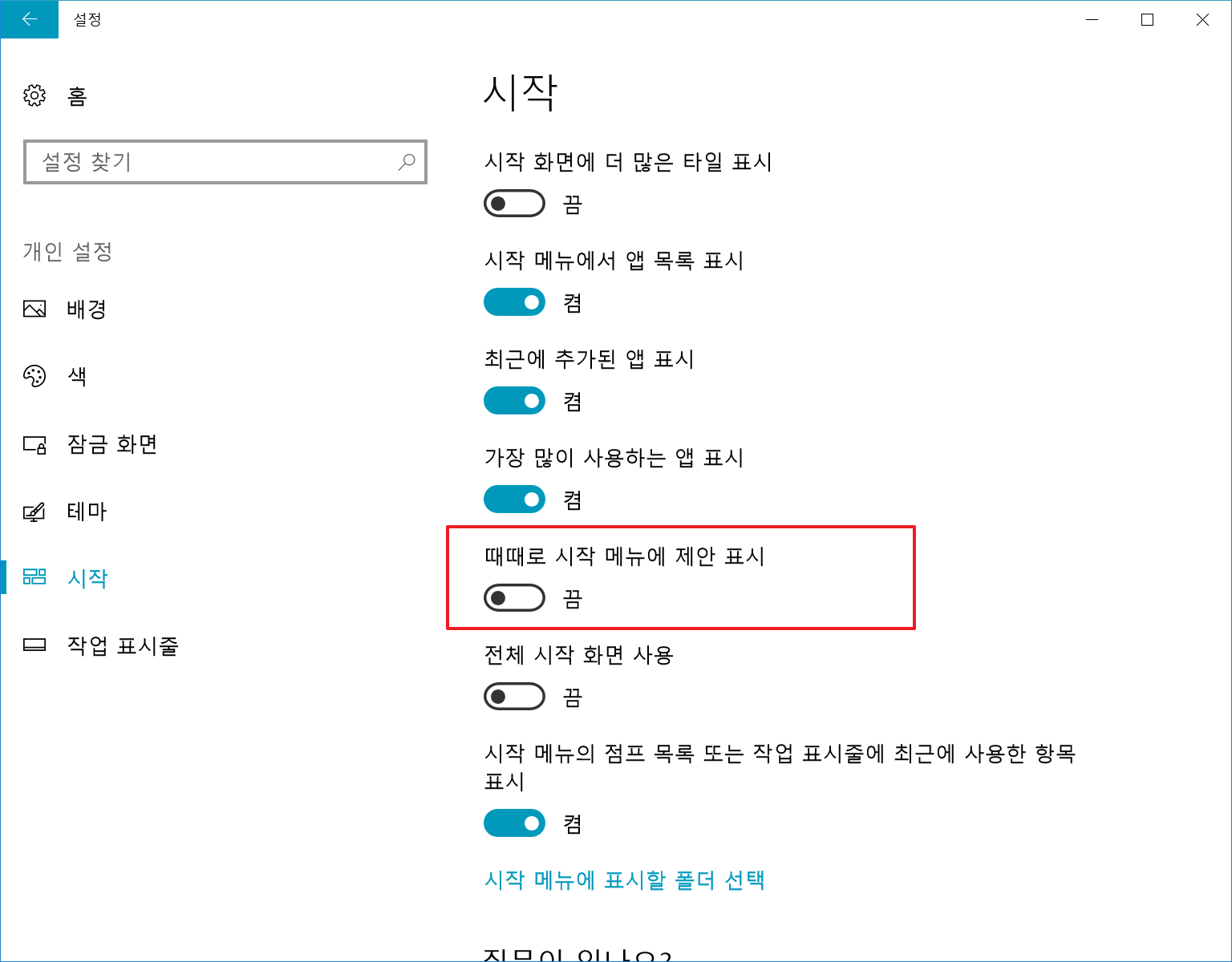
만약 최근에 사용한 항목의 이력을 지우고 싶으시면 아래쪽에 있는 ‘시작 메뉴의 점프 목록 또는 작업 표시줄에 최근에 사용한 항목 표시’ 항목도 체크를 없애시면 됩니다.
14 Oct 2016
|
Android
UX
Android에서 ListView 샘플입니다. ListView는 제일 많이 사용하는 UI 컴포넌트 중
하나이다보니 코드 재활용이 빈번합니다. 그래서 여기 템플릿으로 활용할 수 있는 예제를
하나 포스팅해봅니다. 참고로 GridView도 똑같은 방법으로 사용하면 됩니다.
ListView의 스크롤 속도를 부드럽고 빠르게 하기 위해서는 디자인 패턴 중
ViewHolder Pattern을
사용합니다. Android에서 XML에서 리소스를 읽어오는 findViewById 함수는 시간이 많이 걸리는 함수입니다.
ViewHolder 패턴을 사용하면 최초에 한 번 findViewById 함수로 찾은 리소스를 Holder
안의 변수에 맵핑을 해놓아서 다음 번에 찾을 때 훨씬 빠르게 찾을 수 있습니다.
(Cache와 같은 원리입니다.)
아래는 ViewHolder 패턴을 적용한 예제입니다.
item_view_log.xml
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:id="@+id/layout_background"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:paddingLeft="15dp"
android:paddingRight="15dp"
android:orientation="vertical">
<TextView
android:id="@+id/timestamp"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="timestamp"
android:textColor="@color/ics_theme_darkblue"
android:textSize="14sp" />
<TextView
android:id="@+id/desc"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="Description"
android:textColor="@color/darkgray"
android:textSize="14sp" />
</LinearLayout>
LogListAdapter.java
public class LogListAdapter extends BaseAdapter {
private final Context mContext;
private ArrayList<BaseInfo> mList;
public LogListAdapter(Context context) {
mContext = context;
}
public void refresh(ArrayList<BaseInfo> list) {
mList = list;
notifyDataSetChanged();
}
@Override
public int getCount() {
if(mList == null) {
return 0;
}
return mList.size();
}
@Override
public BaseInfo getItem(int position) {
if(mList == null) {
return null;
}
return mList.get(position);
}
@Override
public long getItemId(int position) {
if(mList == null) {
return 0;
}
return position;
}
@Override
public View getView(int position, View convertView, ViewGroup parent) {
ItemHolder holder = null;
View row = convertView;
if(row == null) {
LayoutInflater inflator = (LayoutInflater) mContext
.getSystemService(Context.LAYOUT_INFLATER_SERVICE);
row = inflator.inflate(R.layout.item_view_log, null);
holder = new ItemHolder();
holder.timestamp = (TextView) row.findViewById(R.id.timestamp);
holder.desc = (TextView) row.findViewById(R.id.desc);
row.setTag(holder);
} else {
holder = (ItemHolder) row.getTag();
}
final BaseInfo item = getItem(position);
if(item != null) {
if(item.getTimestamp() == 0) {
holder.timestamp.setVisibility(View.GONE);
} else {
String timestamp = SnowTimeUtil
.getTimeAsString(STRING_FORMAT.TIMESTAMP_FORMAT, item.getTimestamp());
holder.timestamp.setText(timestamp);
holder.timestamp.setVisibility(View.VISIBLE);
}
holder.desc.setText(item.toString());
}
return row;
}
class ItemHolder {
TextView timestamp;
TextView desc;
}
;
}
그 다음에는 ListView나 GridView를 배치해놓고 setAdapter() 메소드를 이용해서 위의 Adapter를 세팅해주면 됩니다.