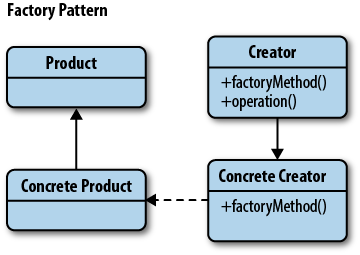
컴포지트(Composite) 패턴의 UML은 다음과 같습니다.
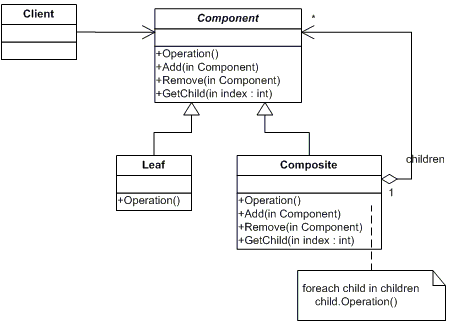
컴포지트 패턴의 개념은 각 객체들을 동일화시키겠다는 것입니다.
조금 다르게 표현하자면 추상적인 상위 클래스 하나를 만들고, 그 클래스를 상속받는 다양한
자식 클래스들을 만드는 것입니다. 그런 다음 그 자식 클래스들을 마치 같은 종류의 클래스
다루듯이 동일시해서 사용하겠다는 패턴입니다.
컴포지트 패턴은 커맨드(Command) 패턴이나 방문자(Visitor) 패턴, 데코레이터(Decorator) 패턴 등에
응용되서 사용되어질 수 있고, 상당히 널리 쓰이는 패턴입니다. 그리고 여기서 더 나아가 트리 구조와
같은 재귀적인(Recursive) 구조를 만들기 위해서도 유용하게 쓰이고 있습니다.
트리 구조의 가장 대표적인 예로는 ‘파일 구조’를 들 수 있습니다. 파일 구조는 폴더와 파일로
이루어져 있으며, 폴더 아래에는 폴더들이 있을 수 있고, 또한 파일들이 있을 수 있습니다.
예제 코드
컴포지트 패턴은 다음과 같이 Component, Leaf, Composite 로 구성됩니다.
public abstract class Component {
// ...
}
public class Leaf extends Component {
// ...
}
public class Composite extends Component {
// ...
private ArrayList list = new ArrayList();
public Component add(Component cp);
public abstract void remove(Component cp);
// ...
}
위에서 언급했던 ‘파일 구조’ 예제를 들어보도록 하겠습니다.
Component
public abstract class Entry {
public abstract String getName();
public abstract int getSize();
public void printList() {
printList("");
}
protected abstract void printList(String prefix);
@Override
public String toString() {
return getName() + "(" + getSize() + ")";
}
}
Leaf
public class File extends Entry {
String name;
int size;
public File(String name, int size) {
this.name = name;
this.size = size;
}
@Override
public String getName() {
return this.name;
}
@Override
public int getSize() {
return this.size;
}
@Override
protected void printList(String prefix) {
System.out.println(prefix + "/" + this);
}
}
Composite
public class Directory extends Entry {
String name;
ArrayList<Entry> list = new ArrayList<>();
public Directory(String name) {
this.name = name;
}
public void add(Entry item) {
list.add(item);
}
public void remove(Entry item) {
list.remove(item);
}
@Override
public String getName() {
return this.name;
}
@Override
public int getSize() {
int size = 0;
for (Entry item: list) {
size += item.getSize();
}
return size;
}
@Override
protected void printList(String prefix) {
System.out.println(prefix + "/" + this);
for (Entry item: list) {
item.printList(prefix + "/" + name);
}
}
}
Main
public class Main {
public static void main(String[] args) {
Directory root = new Directory("root");
Directory user = new Directory("user");
Directory snowdeer = new Directory("snowdeer");
Directory media = new Directory("media");
Directory image = new Directory("image");
Directory music = new Directory("music");
Directory video = new Directory("video");
root.add(user);
root.add(media);
user.add(snowdeer);
media.add(image);
media.add(music);
media.add(video);
snowdeer.add(new File(".bashrc", 42));
snowdeer.add(new File(".profile", 36));
image.add(new File("cat.png", 122));
image.add(new File("dog.png", 56));
image.add(new File("bird.png", 465));
music.add(new File("twice.png", 4382));
music.add(new File("apink.png", 7726));
video.add(new File("frozen.mp4", 341242));
root.printList();
}
}