스트래티지(Strategy) 패턴의 UML은 다음과 같습니다.
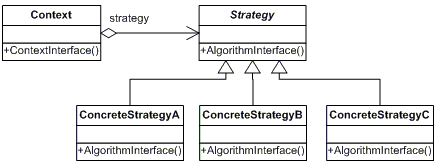
디자인 패턴 중에 가장 많이 쓰이는 패턴 중 하나입니다. 이름을 보면 ‘전략’이라는 뜻을 의미하고 있고,
실제로 알고리즘 등을 캡슐화하여 쉽게 교체해서 쓸 수 있도록 해주는 디자인 패턴입니다. 게임 등에서
난이도나 적들의 인공지능 들을 동적으로 쉽게 변경할 때도 많이 쓰입니다.
예제
Strategy 패턴 예제로 가장 많이 사용되고 있는 오리(Duck) 클래스를 예로 들도록 하겠습니다.
public abstract class Duck {
public Duck() {}
public abstract void display();
public void fly() {
System.out.println("Flying...");
}
public void quack() {
System.out.println("Quack! Quack! Quack!");
}
}
Duck이라는 추상 클래스가 있습니다. fly()와 quack() 메소드는 구현이 되어 있고, display() 메소드는
상속받아서 구현하도록 되어 있습니다.
이제 상속을 이용해서 노란 오리, 청둥 오리, 집 오리 등등 다양한 오리 클래스를 만들 수 있습니다.
상속의 한계점
하지만, ‘모형 오리’를 만들어야 하는 경우가 발생했습니다. 모형 오리는 날지도 못하고, 소리도 내지 못합니다.
물론, 상속을 이용해서 다음과 같이 fly() 메소드와 quack() 메소드 내부를 비워둔채로 구현해도 됩니다.
public class ModelDuck extends Duck {
@Override
public void display() {
System.out.println("This is a ModelDuck.");
}
public void fly() {}
public void quack() {}
}
이와 같은 방식으로 향후 추가될지도 모르는 ‘노란 모형 오리’, ‘태엽으로 움직이는 모형 오리’, ‘건전지로 움직이는 모형 오리’ 등 다양한 오리 클래스들도 모두 구현할 수 있습니다.
하지만, 수십/수백개의 클래스를 각각 만들어서 구현하고 관리하는 건 여간 번거로운 일이 아닐 수 없습니다. 특히 프로젝트 초기에는 모형 오리들이 말을 못했지만, 나중에 출시되는 제품들은 말을 할 수 있게 바꿔야 한다면, 각각의 클래스들을 전부 수정하는 것도 쉬운 일이 아닙니다.
Strategy 패턴 적용
이와 같은 경우 Strategy 패턴을 적용할 수 있습니다. Strategy 패턴은 각각의 알고리즘들을 캡슐화해서 쉽게 교체할 수 있게 할 수 있습니다.
여기서 fly()와 quack()라는 각각의 행동을 캡슐화할 수 있습니다. 예를 들어 각각의 행동을 IFlyBehavior, IQuackBehavior이라는 인터페이스로 치환할 수 있습니다.
public interface IFlyBehavior {
void fly();
}
public interface IQuackBehavior {
void quack();
}
그리고 Duck 클래스는 다음과 같습니다.
public abstract class Duck {
IFlyBehavior iFlyBehavior;
IQuackBehavior iQuackBehavior;
public Duck() {}
public abstract void display();
public void performFly() {
iFlyBehavior.fly();
}
public void performQuack() {
iQuackBehavior.quack();
}
public void setFlyBehavior(IFlyBehavior fb) {
iFlyBehavior = fb;
}
public void setQuackBehavior(IQuackBehavior fb) {
iQuackBehavior = fb;
}
}
각 행동들을 구현
fly()와 quack()라는 행동을 인터페이스로 정의했기 때문에 각 행동군들을 묶어서 클래스로 구현해줍니다.
public class FlyWithWings implements IFlyBehavior {
@Override
public void fly() {
System.out.println("Fly with wings...");
}
}
public class Quack implements IQuackBehavior {
@Override
public void quack() {
System.out.println("Quack! Quack! Quack!");
}
}
날지 못하는 오리들을 위한 NoFly 클래스도 만들어줍니다.
public class NoFly implements IFlyBehavior {
@Override
public void fly() {
System.out.println("I can not fly.");
}
}
이런 식으로 각 행동들을 알고리즘군으로 묶어서 캡슐화를 해주면, 각각의 오리 클래스들의 행동을 쉽게 구현하고 제어할 수 있게 됩니다.
오리 클래스 구현
모형 오리 클래스는 다음과 같습니다.
public class ModelDuck extends Duck {
public ModelDuck() {
setFlyBehavior(new NoFly());
setQuackBehavior(new NoQuack());
}
@Override
public void display() {
System.out.println("I am a ModelDuck.");
}
}
사용 예제
다음과 같은 코드를 이용해서 ‘ModelDuck’ 인스턴스를 만들고, 나중에 Fly 동작을 동적으로 변경이 가능합니다.
public class Main {
public static void main(String[] args) {
Duck duck = new ModelDuck();
duck.display();
duck.performFly();
duck.performQuack();
// change the behavior
duck.setFlyBehavior(new FlyWithWings());
duck.performFly();
}
}
